一致性哈希概念
- 维基百科的定义
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对K/n 个关键字重新映射,其中K是关键字的数量,n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
一致性哈希算法提出了动态变化的Cache环境中,判定哈希算法好坏的四个定义:
- 平衡性:哈希的结果尽可能分布到所有的缓存中,充分利用缓存空间。
- 单调性:举例说吧,本来有ABC三个缓存,数据1存储在B中,现在添加了D缓存进去,则数据1只会分布在B或者D中,不会分配到AC中。
- 分散性:分散性是同一个数据被映射到不同的缓存中,需要避免
- 负载:一个缓冲区被多个用户映射为不同的内容,需要降低缓冲的负载。
传统哈希算法
针对分布式场景,假定有1000W个数据项,100个存储接待你,一个数据的存储位置为该数据的Hash值对服务器数量取余,这样可以将数据尽可能的分散到各个服务器上。
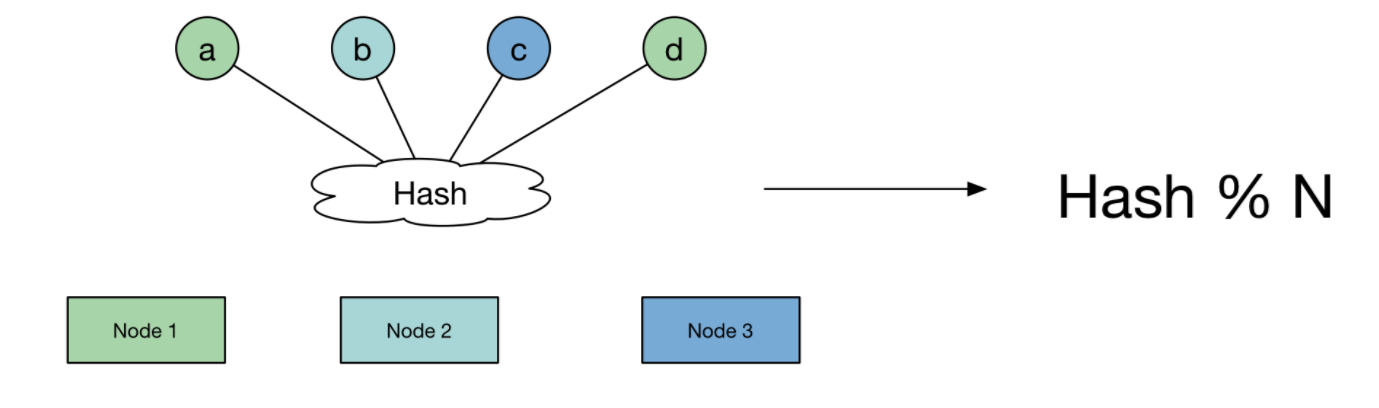
这种哈希方案的优点是每个节点的的数据量是相仿的,相对均衡,但是当在集群里面增加一台服务器,或者减少一台服务器的话,几乎所有的缓存都会失效,需要重新哈希。
|
|
上面的例子中是用普通哈希方法来做的,输出结果如下:
|
|
可以看出,一共1000万个数据,添加或者减少一个节点,进行重新哈希,则990万个数据需要改变存储位置。也就是说990万个缓存不能命中,实际场景中这明显是不能接受的,因此提出了一致性哈希来解决这个问题。
一致性哈希
原理
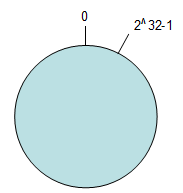
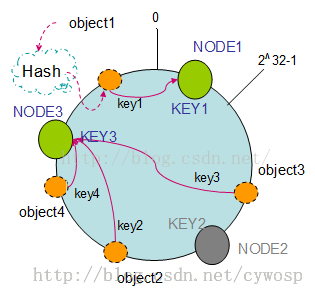
- 唤醒hash空间:按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,也就是0-2^32-1的数字空间中,将其收尾相连,形成一个环空间。
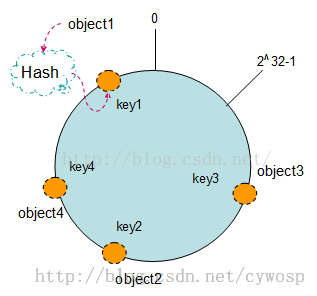
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4;
将数据通过一定的哈希算法处理后映射到环上
将服务器通过哈希算法映射到环上,和数据的哈希算法是一样的,环上的数据,顺时针遇到的第一个服务器就是该数据的存储位置。假定有三个服务器节点。
Hash(NODE1) = KEY1;
Hash(NODE2) = KEY2;
Hash(NODE3) = KEY3;
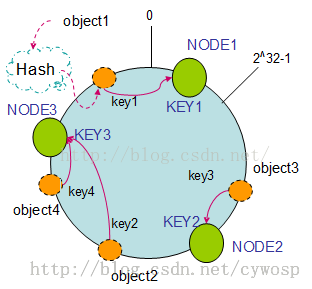
由于哈希环是不会变更的,因此一个数据可以快速的知道他的真正的存储位置。
服务器的删除与添加
不同于传统哈希求余方法,一致性哈希算法在增加或者删除服务器节点是,需要换位置的节点很少,性能很高。
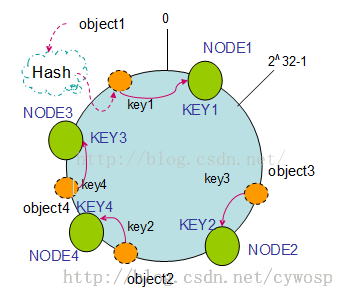
删除服务器节点,如果NODE2出现故障,则从集群里面溢出,那么object3会迁移到Node3中,其他数据的位置不变。
添加服务器节点,向集群里面添加新的 首先将其映射到环中,通过顺时针迁移的规则,object2会迁移到NODE4中,其他对象不会发生改变。数据迁移的数量很小,很适合分布式集群。
java示范
|
|
运行结果为:
|
|
可以看出添加一个节点之后,要修改的数据只有十万个,效率很高。
虚拟节点
上面可以明确看出,一致性哈希算法满足了单调性和负载均衡的特性以及一般hash算法的分散性,平衡性的体现通过虚拟节点来实现。哈希算法是不保证平衡的,如值部署了NODE1和NODE3的情况,object1存储到NODE1中,其他的都存到NODE3中,这样就非常不平衡了。因此引入了虚拟节点。
虚拟节点:实际上是及其在哈希空间中的复制品,一个实际的节点对应了若干个虚拟节点,这样对应个数也成为复制个数,虚拟节点在哈希空间中以哈希值排列。新建两个复制节点之后可以看到节点分配变得很均衡。
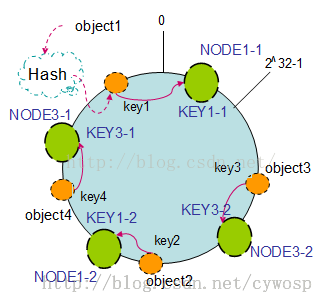
其中涉及了哈希虚拟节点到实际节点的转换,其实只是一个简单的映射:
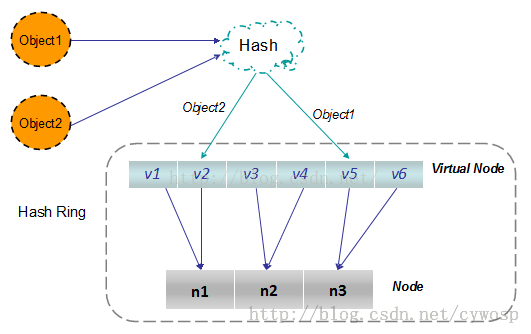
而在实际的场景中,可以通过对真实节点进行编号来生成相应的虚拟节点。如真实节点的IP为192.168.10.11,则虚拟节点可以设置为192.168.10.11#1,192.168.10.11#2。


