上一节总结了ActiveMQ的使用,主要的还是总结了在项目中直接使用和用Spring集成使用。这一节要进一步深入ActiveMQ,学习其内部的原理性的东西。
Session
ActiveMQ消息的发送和接收到离不开Session的建立,首先查看Session的源码:
|
|
而ActiveMQ的Session的创建需要通过Connection的createSession方法,该方法需要设置两个参数,第一个参数表示是否支持事务,第二个参数表示签收模式。
|
|
所谓的签收模式也就是消费者在收到消息之后,需要通知消息服务器收到了消息。当消息服务器收到回执之后,本条消息将失效。而如果消费者收到了消息却并不签收,则本条消息继续有效,可能会被其他消费者消费。
- AUTO_ACKNOWLEDGE :表示消费者接收到消息时自动签收
- CLIENT_ACKNOWLEDGE :消费者接收消息之后需要手动签收
- DUPS_OK_ACKNOWLEDGE :签收不签收都可以,要求消费者可以容忍重复消费。
实际中更加推荐采用手动签收,理论上说,消费者收到消息不代表消息传递的结束,只有当消费者正确处理了消息才是整个消息传递流程的终点。因此如果自动签却没有成功处理收会导致消息丢失。
消息顺序消费
消息优先级
MessageProvider的send方法存在多个重载方法:
|
|
而我们在创建生产者时指定了Destination,也可以在send的时候指定。而且实际工程中的业务逻辑会更加复杂,可能会存在各种判断决定消息发往哪个地址,因此不推荐在创建MessageProducer的时候创建Destination。
消息优先级,0-9。其中0-4为普通消息,5-9为加急消息,消息的默认级别是4。但是实际上,优先级只是个理论上的概念,ActiveMQ并不能保证消费的顺序性。
顺序消费
当我们需要对传入的消息设定一个固定的顺序的时候,比如商城项目中用户下单,支付,发货就是有严格的先后顺序的,不可能先发货在支付。这是或我们需要保证ActiveMQ的顺序执行。
- 一个简单的思路是根据用户ID做一个哈希表,将消息定位到不同的队列上,从而可以使得同一个用户的消息将发往同一个队列。 然后对于同一个队列三个消息,比如订单消息,支付消息,发货消息,将其先后交付给订单系统,支付系统,物流系统进行处理。这个处理过程是同步的,但是在分布式场景下,并不会降低系统的处理性能。
消息的同步与异步
接收消息,可以通过消费者的receive方法,这种方法是client端主动接收消息,也就是同步接收。需要写一个死循环来不停的接受消息。而ActiveMQ提供了异步接收的方法。其实在上一节已经使用了,但是这次单独写出来。原理很简单,我们设置一个消息监听的机制,当队列上有消息了,则回调追星messageListener接口的onMessage方法。这次贴一个我商城里面使用的Listener实现类,实现后台商品添加和索引库的同步,简单逻辑是收到商品添加事件消息之后,根据id去数据库里面查询,然后添加到document中,加到索引库。
|
|
P2P 和 Pub/Sub
两种消息模式,去网上找了两张图,上一节其实已经介绍了,但是没有图还是不直观
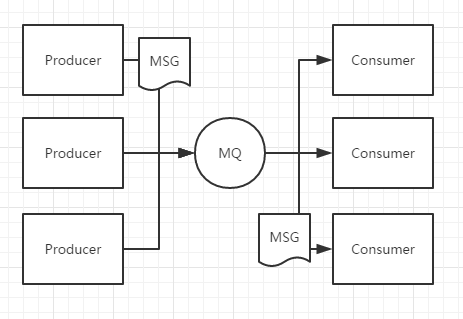
- 一对一通信,一个生产者一个消费者
- 发布订阅模式,发布一条消息,所有订阅了该目标的消费者都会收到消息。
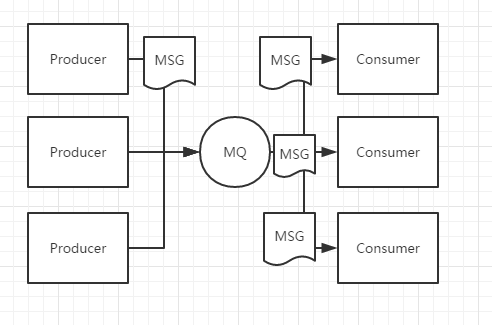
如果消费者重启了,这个消费者会丢失一些消息,为了避免消息丢失,ActiveMQ采用了持久化机制来保存消息。
消息化订阅
持久化订阅就是如果消费者宕机,则将消息暂存在ActiveMQ中,等待消费者正常工作再发送给消费者。首先为消费者设定一个标识ID,然后创建爱你消费者的时候调用session的createDurableSubscriber方法来进行持久化订阅。
ActiveMQ持久化机制
为了避免意外宕机丢失信息,需要做到重启后可以恢复消息队列,消息系统一般都会采用持久化机制。ActiveMQ的持久化消息机制有JDBC、AMQ、KahaDB和LevelDB。在发送者将消息发送出去后,消息中心首先将消息存储到本地数据文件、内存数据库或者远程数据库,然后试图将消息发送给接受者,发送成功则将消息从存储中删除,失败则继续尝试。
消息中心启动之后首先要检查指定的存储位置,如果有未发送成功的消息,则需要把消息发送出去。
JDBC持久化方式
使用JDBC持久化方式,数据库会创建三个表:activemq_msgs,activemq_acks,activem_lock。其中activemq_msgs用来存储消息,Queue和Topic都存储在这个表中。
- 配置方式
配置持久化的方式,需要修改conf/activemq.xml文件,首先定义一个mysql-ds的MySQL数据源,然后在persistenceAdapter节点中配置JDBCPersistenceAdapter并且引用刚才的数据源。dataSource指定持久化数据库的Bean,createTablesOnStartup的核定是否在启动时创建数据库表,默认值为true,一般第一次启动设置为true,后面改成false。
|
|
- 数据库表信息
activemq_msgs用于存储消息,Queue和Topic都存储在这个表中:
| 列明 | 内容 |
|---|---|
| ID | 自增的数据库主键 |
| CONTAINER | 消息的Destination |
| MSGID_PORD | 消息发送者客户端的主键 |
| MSG_SEQ | 发送消息的顺序,MSGID_PORD+MSG_SEQ可以组成JMS的MessageID |
| EXPIRATION | 消息的过期时间, 存储的是从1970-01-01到现在的毫秒数 |
| MSG | 消息本体的Java序列化对象的二进制数据 |
| PRIORITY | 优先级 0-9 |
activemq_acks用于存储订阅关系。如果是持久化Topic,订阅者和服务器的订阅关系在这个表保存:
| 列明 | 内容 |
|---|---|
| CONTAINER | 消息的Destination |
| SUB_DEST | 如果是使用Static集群,这个字段会有集群其他系统的信息 |
| CLIENT_ID | 每个订阅者都必须有一个唯一的客户端ID用以区分 |
| SUB_NAME | 订阅者名称 |
| SELECTOR | 选择器,可以选择只消费满足条件的消息。条件可以用自定义属性实现,可支持多属性AND和OR操作 |
| LAST_ACKED_ID | 记录消费过的消息的ID |
表activemq_lock在集群环境中才有用,只有一个Broker可以获得消息,称为Master Broker,其他的只能作为备份等待Master Broker不可用,才可能成为下一个Master Broker。这个表用于记录哪个Broker是当前的Master Broker。
AMQ方式
性能高于JDBC,写入消息时,会将消息写入日志文件,由于是顺序追加写,性能很高。为了提升性能,创建消息主键索引,并且提供缓存机制,进一步提升性能。
每个日志文件的大小是有限制的,默认为32M,可以自行配置。当超过这个大小,系统会重新建立一个文件,当所有消息都消费完成,系统会删除这个文件或者归档。
主要缺点在于AMQ Message会为每一个Destination创建一个索引,如果使用了大量的Queue,索引文件的大小会占用很多磁盘空间,而由于索引巨大,Broker崩溃,重建索引的速度非常慢。
配置方法:
|
|
虽然AMQ性能高于KahaDb方式,但是由于重建索引时间过长,索引占用磁盘空间过大,实际项目中并不推荐使用,了解即可。
KahaDB方式
KahaDB是从ActiveMQ5.4开始默认的持久化插件。KahaDB恢复时间远远小于其前身AMQ并且使用更少的数据文件,可以完全替代AMQ。
KahaDB的持久化同样是基于日志文件,索引和缓存的。
- 配置方式如下,其中directory用来指定持久化消息的存储目录,journalMaxFileLength用来指定保存消息的日志文件大小,具体根据你的实际应用配置。
|
|
KahaDB主要特性:
- 日志形式存储消息
- 消息索引以B-Tree结构存储
- 完全支持JMS事务
- 支持多种恢复机制
KahaDB的结构
消息存储在基于文件的的数据日志中。如果消息发送成功,变标记为可删除。系统会周期性的清除或者归档日志文件。消息文件的位置索引存储在内存中,这样能快速定位到文件。定期将内存中的消息索引保存到metadata store中,避免大量消息未发送时,消息索引占用过多内存。
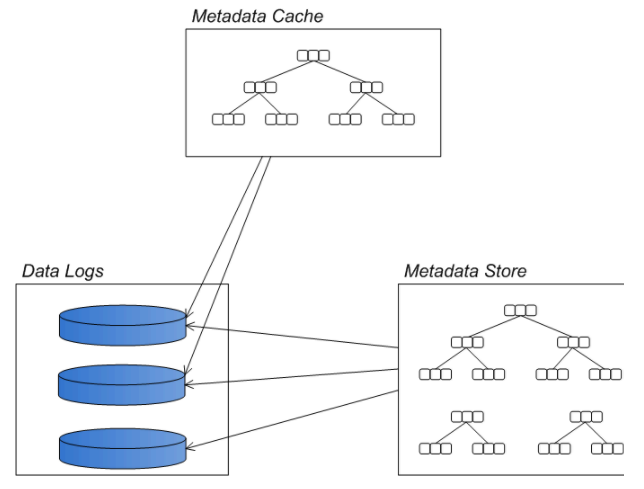
Data logs:Data logs用于存储消息日志,消息的去哪补内容都在Data logs中。同AMQ一样,一个Data logs文件大小超过规定的最大值,会新建一个文件,同样是在文件尾部追加,写入性能很快。每个消息在Data logs中有计数引用,所以当一个文件里所有的消息都不需要了,系统会自动删除文件或放入归档文件夹。
Metadata cache:缓存用于存放在线消费者消息。如果消费者已经快速的消费完成,name这些消息就不需要写入磁盘了。Btree索引会根据MessageID创建索引,用于快速的查找消息,这个索引同样维护持久化订阅者与Destination的关系,以及每个消费者消费消息的指针。
Metadata store:在db.data文件中保存消息日志中消息的元数据,也是一B-Tree结构存储的,定时从Metadata cache更新数据。Metadata store也会备份一些在消息日志中存在的信息,这样可以让broker实例快速启动。几遍metadata store文件被破坏或者删除了,broker可以读取data logs恢复过来,只是速度回很慢。
LevelDB
- ActiveMQ5.6之后推出的持久化引擎LevelDB。
- 默认方式仍然是KahaDB,LevelDB的持久化性能要高于KahaDB。
- LevelDB主要用于Master-Slave方式的主从复制数据。


