高级特性
掌握了Python的数据类型,语句和函数,基本上就可以编出很多有用的程序了,比如构造一个1,3,5,...,99的列表,可以通过循环实现:
|
|
取list的前一半元素,也可以通过循环实现。
但是Python中,代码不是越多越好,而是越少越好。代码不是越复杂越好,而是越简单越好。
基于这一思想,我们开始介绍Python中非常有用的高级特性,1行代码能实现的功能,绝对不用五行代码。
[TOC]
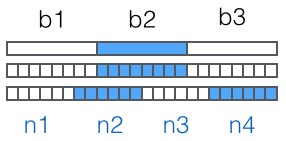
切片
取一个list或者tuple的部分元素是非常常见的操作,比如,一个list如下:
|
|
取前三个元素,应该怎么办?
笨方法:
该方法如果扩展之后让去N个元素就没有办法了。取N个元素,也就是取序号为0-N-1的元素,可以用循环:
|
|
或者:
|
|
对这种经常取指定索引范围的操作,用循环身份繁琐,因此,Python提供了切片(slice)操作符,能大大简化这种操作。
对应上面的问题,取前三个元素,用一行代码就可以搞定:
|
|
L[0:3]表示,从索引0开始取,取到索引3为止,但不包括3.即索引取0,1,2,正好是三个元素。如果第一个索引是0,还可以省略,也可以从索引1开始,取出两个元素。
类似的,既然Python支持L[-1]取出倒数第一个元素,那么他同样支持倒数切片:
|
|
切片操作十分有用。我们先创建一个0-99的数列:
|
|
可以通过切片取出某一段数列,比如前十个,后十个,11-20等:
前十个数,每两个去一个:
所有数,每五个取一个:
如果什么都不写,只写[:]就可以复制一个list。
tuple也是list的一种,唯一区别是tuple不可变。因此tuple也可以用切片操作,操作的结果仍然是tuple:
|
|
字符串xxx也可以看成是一种list,每一个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍然是字符串:
|
|
在许多编程语言中,针对字符串提供了很多种截取函数,如substring,其实目的就是对字符串进行切片。Python没有针对字符串的截取函数,只需要切片一个操作就可以完成,非常简单。
小结
有了切片操作,很多地方循环就不需要了。Python的切片非常灵活,一行代码就可以实现多行循环才能完成的操作
迭代
如果给定一个list或者tuple,我们可以通过for循环来遍历这个list或者tuple,这种遍历我们称为迭代(iteration)。
在Python中,迭代是通过for...in来完成的,而很多语言如Java,迭代是通过下标完成的,比如:
|
|
可以看出,Python的for循环抽象程度要高于Java的for循环,因为Python的for循环不仅可以用于list或tuple上,还可以用于其他可迭代对象上,list这种数据类型虽然有下标,但很多其他数据类型是没有下标的。只要是可迭代对象,无论有无下标,都可以迭代,比如dict就可以迭代:
|
|
其中因为dict的存储不是按照list的方式顺序排列,所以迭代出来的顺序很可能不一样。默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k,v in d.items()。
由于字符串也是可迭代对象,因此,也可以用作for循环:
|
|
所以,当我们使用for循环时,只要作用于一个可迭代对象,for循环就可以正常运行,而我们不太关心该对象是list还是其他的数据类型。
如何判断一个对象是可迭代对象呢?方法是通过collections模块的Iterable类型判断:
|
|
如果对list实现类似Java那样的下标循环怎么办?Python中内置的enumerate函数可以把一个list编程索引-元素对,这样就可以在for循环中同事迭代索引和元素本身:
|
|
上面的for循环里,同时引用了两个变量,在Python里面是很常见的:
|
|
小结
任何可迭代对象都可以作用于for循环,包括我们自定义的数据类型,只要符合迭代条件,就可以使用for循环。
列表生成式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式,如下:
|
|
但是如果要生成[1*1,2*2,3*3,...,10*10],方法一是循环:
|
|
但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的list:
|
|
写列表生成式时,把要生成的元素x*x放在前面,后面跟上for循环,就可以把list创建出来。
for循环后面还可以加上if判断,这样我们局可以筛选出仅偶数的平方:
|
|
还可以使用两层循环,可以生成全排列:
|
|
三层和三层以上的循环就很少用了。
运用列表生成式可以写出非常简洁的代码。例如,列出当前目录下的所有文件和目录名,可以通过一行代码实现:
|
|
for循环其实可以同时使用两个甚至多个变量,如dict的items()可以同时迭代key和value:
|
|
因此列表生成式也可以使用两个变量来生成list:
|
|
最后把一个list中的所有字符串变为小写:
|
|
练习
L1=[‘Hello’,’World’,18,’Apple’,None],添加if语句,期待L2=[‘hello’, ‘world’, ‘apple’]
|
|
生成器
通过列表生成式,我们可以直接创建一个列表。但是受到内存的限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的空间,如果我们仅仅需要访问前面几个元素,后面的绝大多数元素占用的空间就被白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环过程中不断推算出后面的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多中方法。第一种很简答,只要把一个列表生成式的[] 改为(),就创建了一个generator:
|
|
可以看出创建L和g的区别仅在于最外层是[]还是(),L是一个list,而g是一个generator。我们可以直接打出list的么一个元素,但是我们怎么打出generator的每一个元素呢,如果要一个一个打,可以通过next()函数来获得generator的下一个返回值:
|
|
我们前面讲过,generator保存的是算法,每次调用next(g),就计算出下一个g的值,直到计算到最后一个元素,没有更多的元素时,抛出stopiteration的错误。generator非常强大,如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。比如著名的斐波拉契数列(Fibonacci),除了第一个和第二个数外,任意一个数可由前面两个数相加得到:
1,1,2,3,5,8,13,21,34…
斐波拉契数列用列表生成式写不出来,但是,用函数可以把它打印出来:
|
|
仔细看,fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑非常类似generator。也就是说,上面个的函数和generator只有一步之遥。要把fib变为generator,只需要把print(b)改为yield b就可以了:
|
|
这就是定义generator的另一种方法。如果一个函数定义包含关键字yield,那么这个函数就不再是一个普通的函数,而是一个generator。
这里最难理解的是generator和函数的执行流程不一样。函数是顺序执行的,遇到return语句或者最后一行函数语句就返回。而变为generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句出继续执行。
举个例子,定义一个generator,一次返回数字1,3,5:
|
|
可以看出,odd()不是普通函数,而是generator,在执行过程中,遇到yield就会中断,下次又继续执行。执行3次之后,没有yield可以执行了,所以第四次调用next(o)就报错。回到fib的例子,我们在循环过程中不断用yield,就会不断中断。当然要给循环设置一个条件来跳出循环,不然就会产生一个无限数列出来。同样的,把函数改为generator之后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代。
|
|
但是使用for循环时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
|
|
练习
杨辉三角,把每一行看做一个list,试着写一个generator,不断输出下一行的list:
|
|
小结
generator是非常强大的工具,在Python中,可以简单的把列表生成式改为generator。要理解generator的工作原理,他是在for循环的过程中不断计算出下一个元素,并在适当的条件结束循环。对于函数改成的generator来说,遇到return语句或者执行到函数体最后一行语句,就要结束generator的指令,for循环随之结束。
请注意区分普通函数和generator函数,普通函数调用直接返回结果,generator函数调用实际返回一个generator对象。
迭代器
我们已经知道,可以直接作用关于for循环的数据类型有以下几种:一类是集合数据类型,如list,tuple,dict,set,str等;一类是generator,包括生成器和带yield的generator function。这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。可以使用isinstance()来判断一个对象是否是Iterable对象:
|
|
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以用isinstance()来判断一个对象是否是Iterator对象:
|
|
生成器都是Iterator对象,但是list,dict,str却不是。把这些Iterable变为Iterator可以使用iter()函数:
|
|
为什么list,dict,str不是Iterator???
这是因为Python的Iterator对象表示一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序的序列,但是我们却不能提前得知序列的长度,只能不断通过next()函数实现按需计算的下一个数据,所以Iterator的计算时惰性的,只有在需要的时候才会计算。Iterator甚至可以表示一个无限大的数据流,例如全体自然数,但是list是永远不可能存储全体的自然数的。
小结
凡是可以用作for循环的对象都是Iterable类型;
凡是可作用关于next()函数的对象都是Iterator类型,他们表示一个惰性计算的序列;
集合数据类型如list,dict,str等都是Iterable,但是不是Iterator,不过可以通过iter()获得一个Iterator对象。·Python上的
for循环本质上是通过不断调用next()函数来实现的:

 `=>
`=>