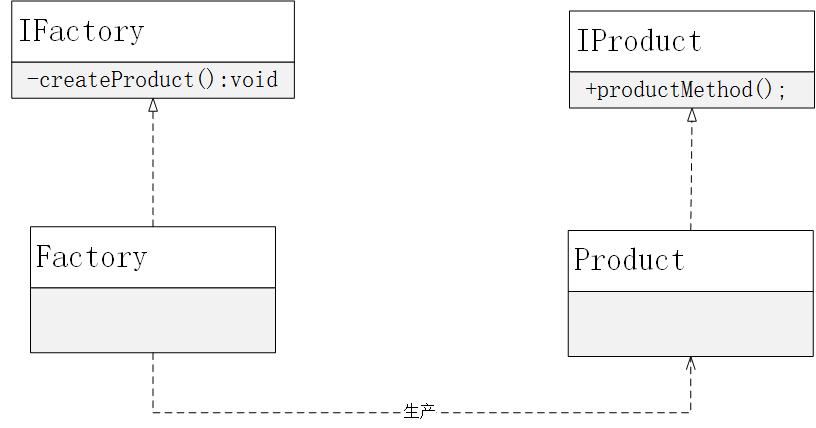
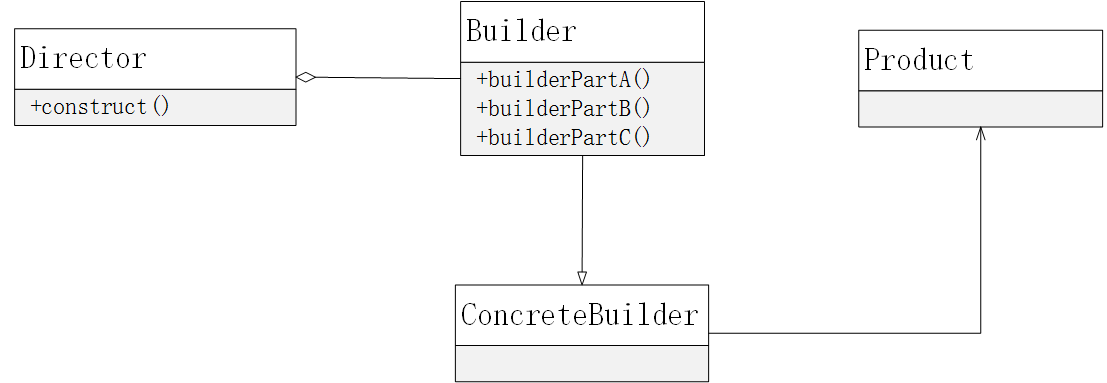
go语言实战 - 并发
第六章 并发
- go语言的并发是指让某个函数独立于其他函数运行的能力
- go语言的并发同步模型来自于通信顺序进程泛型(Communication SequentialProcess,CSP)
- CSP是一种消息传递模型,通过在goroutine之间传递数据来传递消息,而非对数据加锁来实现同步访问
- go引入了新数据类型,通道channle
并发与并行
操作系统的进程与线程
- 进程包含了应用程序在运行时需要用到和维护的各种资源的容器,如内存地址空间,文件,设备的句柄及线程
- 线程是一个执行空间,被操作系统调度来执行代码
操作系统会在物理处理器上调度线程来运行,go语言会在逻辑处理器上调度goroutine来运行
- go语言默认给每个可用的物理处理器分配一个逻辑处理器
- 一个逻辑处理器可以调度无数个goroutine
- 创建一个goroutine并准备运行
- goroutine会首先进入调度器的全局运行队列中
- 调度器将队列中的goroutine分配给一个逻辑处理器,也就是将goroutinue放置到逻辑处理器对应的本地运行队列中
- 本地运行队列中的goroutine会等待到自己被分配的逻辑处理器执行
goroutine
- runtime.GOMAXPROCS可以更改调度器可以使用的逻辑处理器的数量
|
|
- 设置一个逻辑处理器的结果
|
|
- 设置多个逻辑处理器的结果
|
|
- 一个正运行的goroutine再工作结束前,可以被停止并重新调度,避免一个goroutine长时间占用逻辑处理器
- runtime包提供了修改go语言运行时配置参数的能力
- 并不是逻辑处理器数量越多越好,需要经过基准测试来评估
竞争状态
- 两个或者多个goroutine访问某个共享资源,则称其处于互相竞争的状态
- runtime.Gosched()强制调度器切换两个goroutine
|
|
锁住共享资源
原子函数
- 原子函数能够以底层的加锁机制来同步访问整醒变量和指针
- atomic包的AddInt64函数会同步整型值的加法,强制同一时刻只能有一个goroutine运行并完成这个加法操作
|
|
- LoadInt64和StoreInt64提供了一种安全地读写一个整型值的方法
|
|
互斥锁
- 互斥锁mutex用于在代码上创建一个临界区,保证统一时间只有一个goroutine可以执行这个临界区代码,修正上述代码如下
- 使用大括号可以使得临界区看起来更加清晰
- 强制退出当前线程之后,如果调度器分配其他线程执行,会因为拿不到临界区的互斥锁而等待,从而保证调度器会分配回当前线程来进行程序继续执行
|
|
通道
- 通道通过发送和接收需要共享的资源,在goroutine之间做同步
- 声明通道时,需要指定将要被共享的数据的类型,可以通过通道共享内置类型,命名类型,结构类型和引用类型的值或者指针
- make关键字来创建通道
<-运算符表示数据的流向
无缓冲的通道
- 无缓冲的通道指的是接手前没有能力保存任何值的通道
- 这种对通道进行发送和接收的交互 行为本身就是同步的,否则会阻塞,发送和接收的goroutine互相依赖
- 网球比赛示例如下
|
|
有缓冲通道
- 有缓冲通道时一种在被接收前能存储一个或多个值的通道
- 并不强制要求goroutine之间必须同时完成接收和发送
- 4个goroutine来完成10个工作可以使用带缓冲的通道来实现
- 需要注意,通道关闭之后是只能从通道读取数据,不能写入,不会有数据丢失
|
|
小结
- 并发是指goroutine运行的时候是互相独立的
- 使用关键字go创建goroutine来运行函数
- goroutine在逻辑处理器上执行,而逻辑处理器则具有独立的系统线程和运行队列
- 竞争状态是指两个或者多个goroutine试图访问同一个资源
- 原子函数和互斥锁提供了一种防止出现竞争状态的方法
- 通道提供了一种在两个goroutine之间共享数据的简单方法
- 无缓冲的通道保证同时交换数据,有缓冲的通道不做这种保证
第七章 并发模式
runner
- runner包用于展示如何通过通道来监视程序的执行时间
- runner包也可以终止程序
- 适合用于定时任务中
|
|
- 函数调用方法
|
|
pool
- pool用于展示如何使用有缓冲的通道实现资源池
|
|
- 连接池的使用代码如下
|
|
work
- work包的目的是展示如何使用无缓冲的通道来创建一个goroutine池
|
|
- 运行函数
|
|
小结
- 可以使用通道来控制程序的声明周期
- 带default分支的select语句可以用来尝试向通道发送或者接受数据,而不会被阻塞
- 有缓冲的通道可以用来管理一组可服用的资源
- 语言运行时会处理好通道的协作和同步
- 使用无缓冲的通道来创建完成工作的goroutines池
- 任何时间都可以用无缓冲的通道来让两个goroutine交换数据,在通道操作完成时一定保证对方接收到了数据