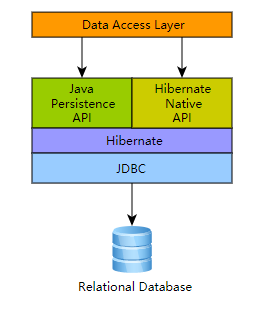
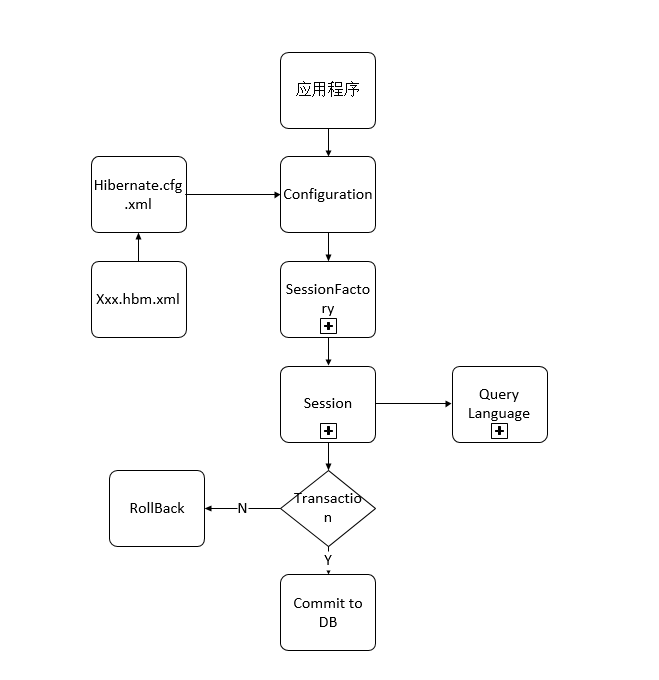
线程池定义
- 多线程的程序可以最大限度的发挥多核CPU的性能,但是如果不对线程进行合理的管控,会影响整体系统的性能。线程虽然相对进程来说很轻量级,但是也要占据一定的内存,新建和销毁也需要时间,不能无节制的创建线程。
- 线程池本质上是一组线程实时处理休眠状态,等待唤醒执行,使用线程池中,创建线程变成了从线程池中获取线程。
- 线程池可以较少创建和销毁线程上所花的时间以及系统资源的开销,同时将当前任务和主线程任务隔离,实现和主线程的异步执行,提高程序的执行效率。
线程池的种类
JDK对线程池的支持如下:

(图片来源:http://www.blogjava.net/xylz/archive/2010/12/21/341281.html)
Java中提供了四个静态方法来创建一个线程池,在线程池中执行任务比为每个任务分配一个线程优势更多,通过重用现有的线程而不是创建新线程,可以在处理多个请求时分摊线程的创建和销毁的开销。当请求到达时,线程已经存在,提高了响应速度。通过配置线程池的大小,可以创建爱你足够多的线程充分利用CPU的多核资源,同时防止线程太多耗尽资源。
newFixedThreadPool()
- 该方法返回一个固定线程数量的线程池。
- 该线程池中的线程数量始终不变。
- 当有一个新的任务提交时,线程池中若有空闲线程,则立即执行
- 如果没有空闲线程,则会将任务保存在一个任务队列中,线程空闲时,处理线程任务队列中的数据
Executors中方法
|
|
使用实例
|
|
newSingleThreadExecutor()
- 该方法返回一个只有一个线程的线程池
- 当有一个新的任务提交时,空闲则执行,否则等待执行
- 确保线程之间的串行执行
Executors中方法
|
|
使用实例
|
|
newCachedThreadPool()
- 返回一个可根据实际情况调整线程数量的线程池
- 线程池中线程的数量不确定
- 任务提交时,复用线程优于新建线程
Executors中方法
|
|
使用实例
|
|
newScheduleThreadPool()
- 返回一个ScheduledExecutorService对象
- 增加了定时执行的功能,如延时执行或者周期执行
Executors中方法
|
|
使用实例
|
|
四种定时执行的方式
|
|
submit
- submit()与execute()类似,区别在于一个有返回值一个没有
- submit()适合生产者消费者模式,与Future一起使用,可以在没有返回结果时阻塞当前线程的作用
- 实现源码:
|
|
ThreadPooLExecutor类
- 线程池中最重要的类
基本参数
|
|
构造方法
|
|
缓存队列的类型
- ArrayBlockingQueue : 有界的数组队列
- LinkedBlockingQueue : 可支持有界/无界的队列,使用链表实现
- PriorityBlockingQueue : 优先队列,可以针对任务排序
- SynchronousQueue : 队列长度为1的队列,和Array有点区别就是:client thread提交到block queue会是一个阻塞过程,直到有一个worker thread连接上来poll task。当线
拒绝策略
- ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
- ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
execute
- 表示向线程池中添加线程,可能会立即执行,也可能不会。
- 无法预知线程的开始和结束
|
|
- ThreadPoolExecutor中,包含了一个任务缓存队列和若干个执行线程,任务缓存队列是一个大小固定的缓冲区队列,用来缓存待执行的任务,执行线程用来处理待执行的任务。每个待执行的任务,都必须实现Runnable接口,执行线程调用其run()方法,完成相应任务。
- ThreadPoolExecutor对象初始化时,不创建任何执行线程,当有新任务进来时,才会创建执行线程。
- 构造ThreadPoolExecutor对象时,需要配置该对象的核心线程池大小和最大线程池大小:
- 当目前执行线程的总数小于核心线程大小时,所有新加入的任务,都在新线程中处理
- 当目前执行线程的总数大于或等于核心线程时,所有新加入的任务,都放入任务缓存队列中
- 当目前执行线程的总数大于或等于核心线程,并且缓存队列已满,同时此时线程总数小于线程池的最大大小,那么创建新线程,加入线程池中,协助处理新的任务。
- 当所有线程都在执行,线程池大小已经达到上限,并且缓存队列已满时,就rejectHandler拒绝新的任务
shutdown
- 放在execute后面
- 表示当前线程池不接受新添加的线程
- 所有线程执行完毕时,回收线程池资源
- 不会马上关闭线程池,执行完已经提交的线程池
|
|
shutdownNow
- 立刻关闭线程池,会引起系统数据异常
|
|
实例
|
|